

我是如何制作知乎问答收集工具的?
标签: Pyhon源码 教程
此贴仅作技术交流,禁止潜伏在论坛的无良商家把我的源码打包了拿出去卖!
此贴仅作技术交流,禁止潜伏在论坛的无良商家把我的源码打包了拿出去卖!
之前发过一款软件知乎问答收集器,没想到有这么多人喜欢,我看到评论区还有和我一样的Pyhon爱好者求源码,那么今天源码来啦!这次的源码跟我以前发的代码思路有点不一样了,这次采用严格面向对象的编程思想来写的代码,小白看起来可能就比较吃力了,所以我大概讲解一下,如果讲得不好也请大佬轻喷,本次编程使用的知识点主要有以下:
- 面向对象的编程方法,代码里一切皆为对象
- Tkinter包的使用,绘出普通用户也能使用的软件界面
- 伪装请求头headers,使网站无法辨认出访问它的是Python还是浏览器。
- 利用cookie登陆,解除未登录用户只能爬取一页的限制。
- 分析ajax请求,推测每个参数代表的意义。
- 利用json包解析返回的json数据
- 用csv包把数据存储在csv文件中(Excel可以直接打开)
一共三个Python文件,第一个文件Spider.py是我第一次写的,单文件补上cookie可以运行没有依赖其它文件。后面的SSpider.py和tk_main.py是我写的图形界面,程序入口为tk_main.py文件,SSpider.py也就是把Spider.py的代码复制过去做了一点点适合图形界面的修改,然后作为包导入tk_main.py使用,发出来的那个软件就是这两个文件进行的打包,代码量较大,我就不全部发在贴子里,而把完整的三个文件代码都分享到Github,但是讲解我就讲解第一个Spider.py文件,后面的图形界面tkinter的话你如果学过一看就懂,没学过我也不好讲,你们就自己看咯。Github源码点击这里就可以看到啦!不会用Github的坛友没关系,我还会在下面的附件传一份!
教程
1. 首先导入所需要的包
import requests
import json
import time
import csv
import re
import requests
import json
import time
import csv
import re
Python的代码一项以简洁著称,所以我们也不需要很多东西,就这五个包,requests用来处理网页请求,json用来处理得到的数据,time把返回的时间戳转化为时间,csv作为文件储存格式,re正则用来消除中文中夹杂的html代码。
2. 定义一个爬虫类
class ContentSpider():
url = \'https://www.zhihu.com/question/300985609\'
headers = {
\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36\',
\'cookie\': \'\' #这里输入你自己的cookie
}
items = []
url = \'https://www.zhihu.com/question/300985609\'
headers = {
\'user-agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36\',
\'cookie\': \'\' #这里输入你自己的cookie
}
items = []
这个爬虫类包含三个属性,分别是url,headers,items,其中
- url指话题目录,如:https://www.zhihu.com/question/19603240
- headers包括user-agent和你的cookie即可
- items是一个列表,我们把爬取到的信息储存在items里面
3. 定义类的构造函数
def __init__(self, offset):
self.console_items = []
self.api = \'https://www.zhihu.com/api/v4/questions/\'+self.url.split(\'/\')[-1]+\'/answers?include=data%5B%2A%5D.is_normal%2Cadmin_closed_comment%2Creward_info%2Cis_collapsed%2Cannotation_action%2Cannotation_detail%2Ccollapse_reason%2Cis_sticky%2Ccollapsed_by%2Csuggest_edit%2Ccomment_count%2Ccan_comment%2Ccontent%2Ceditable_content%2Cvoteup_count%2Creshipment_settings%2Ccomment_permission%2Ccreated_time%2Cupdated_time%2Creview_info%2Crelevant_info%2Cquestion%2Cexcerpt%2Crelationship.is_authorized%2Cis_author%2Cvoting%2Cis_thanked%2Cis_nothelp%2Cis_labeled%2Cis_recognized%2Cpaid_info%2Cpaid_info_content%3Bdata%5B%2A%5D.mark_infos%5B%2A%5D.url%3Bdata%5B%2A%5D.author.follower_count%2Cbadge%5B%2A%5D.topics&limit=10&offset={}&platform=desktop&sort_by=default\'.format(offset) #每次请求10条数据,从format处开始
self.get_data()
self.sort_data()
self.write_csv()
self.console_print()这里我们在构造函数里又给类赋予了两个属性,因为这两个属性是动态的,所以在构造函数里定义,大家可以看到类的api属性有很大一串,这个是怎么得来的呢?
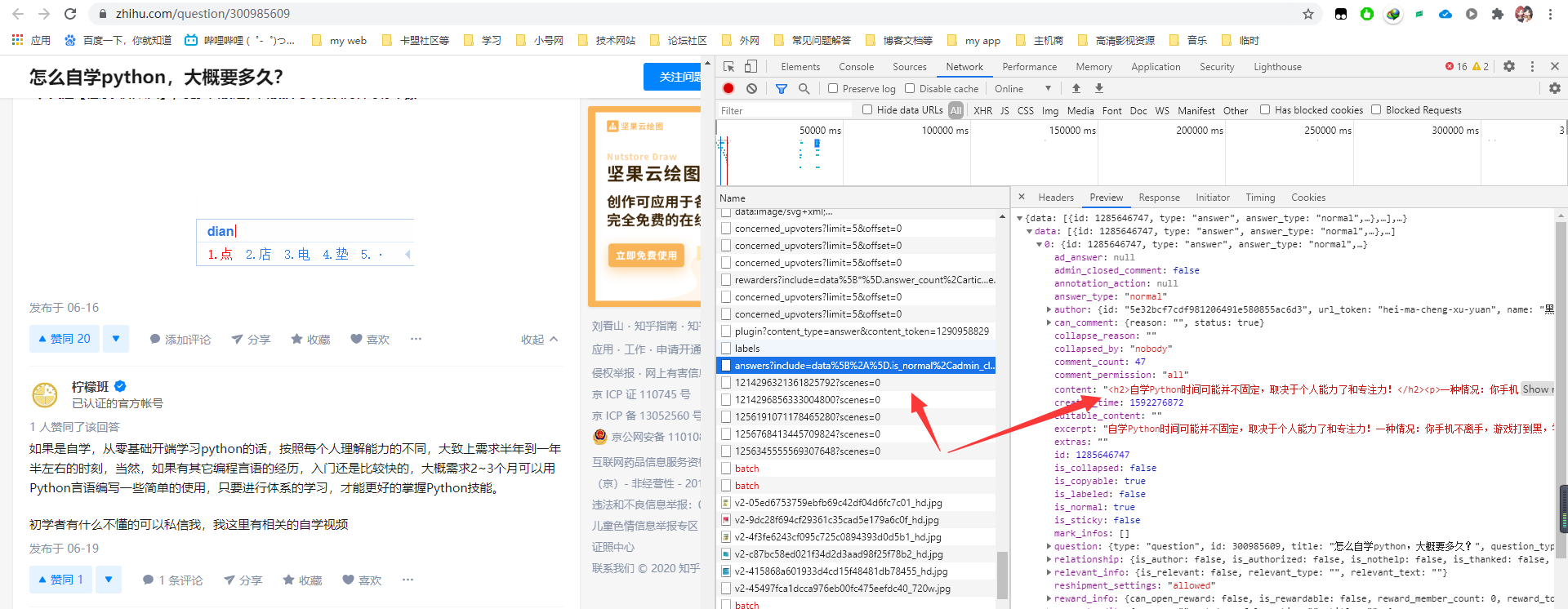
- 首先打开某个问答的话题网址,如:https://www.zhihu.com/question/300985609。然后按F12,浏览器自动抓包,经过一个一个的筛选,我们最终照到了如图所示的关键包,那为什么是这个包呢?因为它里面包含了我们所需要的信息,当然如果你找的多,就会有直觉了,能找的快一些,刚开始都得慢慢找,后面心里就明白了规律。
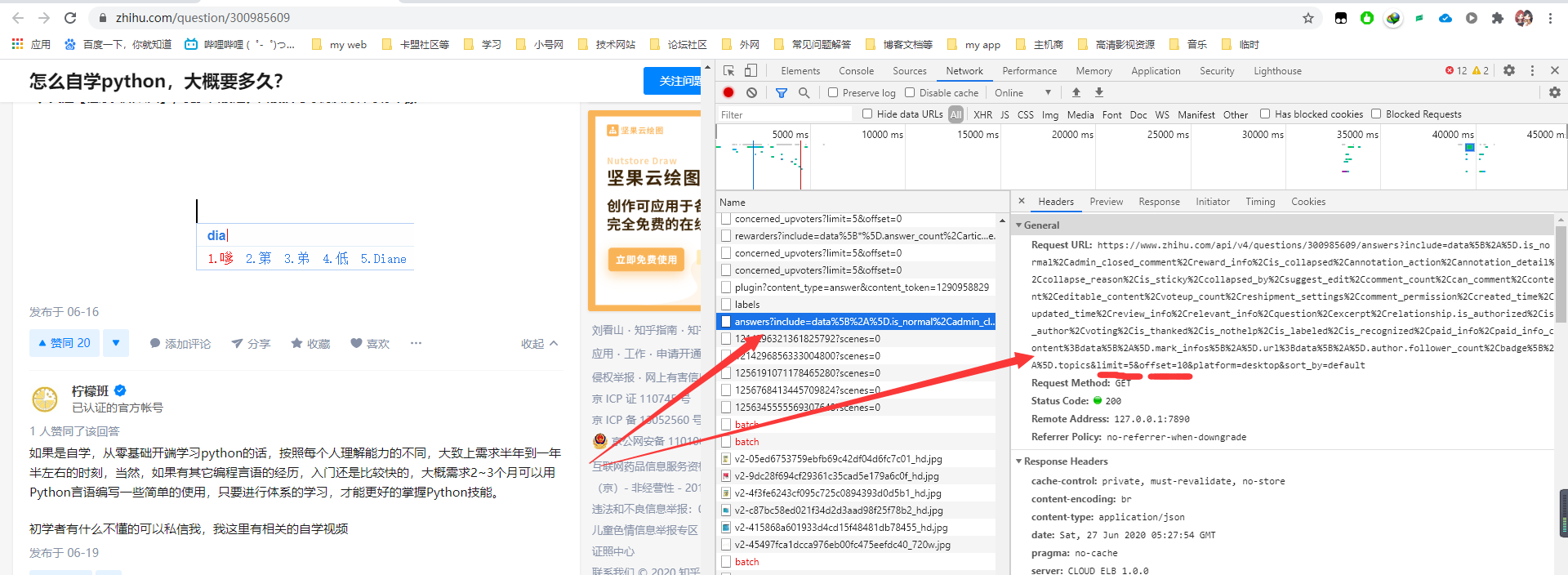
- 既然找到了我们需要的包,那么我们来看看这个包是怎么得到的,就是右边这一长串链接了,我们可以看到最后有两个参数,offset和limit,然后我把这段链接放在Python里模拟请求,并改变这两个参数的值发现,offset就表示你从第几个回答开始,limit是一次请求多少个回答,那这样就简单了,我们只需要设定limit为某一个值,我这里设置为10,也可以设置为其它的,一般在5-20都可以,然后将offset改变,每次增加limit的值个,就可以连续请求,直到最后没有数据才会停止了。这就是api属性的由来。
4. 定义类的方法
def get_data(self): #通过ajax请求得到json数据
rsp = requests.get(self.api, headers=self.headers)
print(rsp.status_code)
self.data = json.loads(rsp.content)[\'data\']
def sort_data(self): #给数据分类,内容content,作者author[name],评论数comment_count,赞成voteup_count,编辑时间戳updated_time
for i in self.data:
id = i[\'id\']
author = i[\'author\'][\'name\']
updated_time = time.localtime(i[\'updated_time\'])
updated_time = time.strftime(\"%Y-%m-%d %H:%M:%S\", updated_time)
voteup_count = i[\'voteup_count\']
comment_count = i[\'comment_count\']
content = i[\'content\']
content = re.sub(\'<(.*?)>\', \'\', content)
link = self.url+\'/answer/\'+str(id)
self.items.append([id, author, updated_time, voteup_count, comment_count, content, link])
self.console_items.append([id, author, updated_time, voteup_count, comment_count, content, link])
def write_csv(self):
with open(\'data.csv\', \'w\', encoding=\'utf-8-sig\') as csvfile:
writer = csv.writer(csvfile)
writer.writerow([\'ID\', \'作者\', \'编辑时间\', \'点赞数\', \'评论数\', \'内容\', \'网址\'])
for item in self.items:
writer.writerow(item)
def console_print(self):
for i in self.console_items:
print(i)我们这个爬虫类不能空有一身属性,还得有技能(类的方法)才行对吧,那我就从上到下一个给它定义了四项技能,分别是。
- 获取数据,即通过requests请求网址来获取数据。
- 整理数据,获取的数据那么繁杂,我们只需要其中的部分数据,所以交给这个函数来处理
- 写入数据,数据整理好后我们可以将其写入csv文件(可直接用Excel打开)
- 显示数据,不论是在代码写好前还是在爬取时,我们都需要关注我们到底爬取了哪些内容,因此我们把相关的结果打印出来,方便我们查漏补缺。
- 首先打开某个问答的话题网址,如:https://www.zhihu.com/question/300985609。然后按F12,浏览器自动抓包,经过一个一个的筛选,我们最终照到了如图所示的关键包,那为什么是这个包呢?因为它里面包含了我们所需要的信息,当然如果你找的多,就会有直觉了,能找的快一些,刚开始都得慢慢找,后面心里就明白了规律。
至此类的属性和方法我们全都定义完毕,现在就很好办了,因为构造函数里已经调用了类的全部方法,所以我们只需要将类实例化即可执行我们的Python代码了。
5. 标明程序入点,将类实例化开始执行代码
if __name__ == \'__main__\':
offset = 0
while True:
spider = ContentSpider(offset)
if not len(spider.data):
print(\'爬取完毕!\')
break
offset += 10
offset = 0
while True:
spider = ContentSpider(offset)
if not len(spider.data):
print(\'爬取完毕!\')
break
offset += 10
这样,我们的程序就写完啦!
总结
我们可以看出来,用面向对象的思想写代码思路将是如此简单轻松,即使网站变更了我们也可以很容的找出需要修改的地方,这次没有用多线程是因为经过我的实际测试,多线程爬取速度过快触发反爬机制而被禁掉,当然如果你非要多线程的话就需要用代(过滤)理IP了,那就是把简单问题搞复杂了,因为每个问题本来也就没多少数据,1000条8秒就可以搞定,就算是10000个回答你也就等一分多钟而已,况且这种回答数很高的问题很少,所以没必要,我们这里只需要用单线程就可以了,也不会占用别人的服务器的资源。
我们可以看出来,用面向对象的思想写代码思路将是如此简单轻松,即使网站变更了我们也可以很容的找出需要修改的地方,这次没有用多线程是因为经过我的实际测试,多线程爬取速度过快触发反爬机制而被禁掉,当然如果你非要多线程的话就需要用代(过滤)理IP了,那就是把简单问题搞复杂了,因为每个问题本来也就没多少数据,1000条8秒就可以搞定,就算是10000个回答你也就等一分多钟而已,况且这种回答数很高的问题很少,所以没必要,我们这里只需要用单线程就可以了,也不会占用别人的服务器的资源。
欢迎大家一起来交流讨论!
-
-
源码.zip
小酒资源吧(www.xiaojiu8.cn)声明:
1. 本站所有资源来源于用户上传和网络,如有侵权请邮件联系站长!603313839@qq.com
2. 请您必须在下载后的24个小时之内,从您的电脑中彻底删除上述内容资源
3. 本站资源售价只是赞助,收取费用仅维持本站的日常运营所需!
4. 不保证所提供下载的资源的准确性、安全性和完整性,源码仅供下载学习之用!
5. 不保证所有资源都完整可用,不排除存在BUG或残缺的可能,由于资源的特殊性,下载后不支持退款。
6. 站点所有资源仅供学习交流使用,切勿用于商业或者非法用途,与本站无关,一切后果请用户自负!



